|
|
|
|
Now that we've cracked a couple of simple, but short, ciphers, let's explore how cryptographers might actually crack some classic ciphers. Note: Remember that this web site contains a number of potentially useful Java applets, which you may choose to use to help you with the work in this assignment. Shift Substitution CiphersA MonoAlphabetic Substitution Cipher maps individual plaintext letters to individual ciphertext letters, on a 1-to-1 unique basis. That is, every instance of a given letter always maps to the same ciphertext letter. The oldest such cipher known is the Caesar cipher, where the mapping involved a simple shift within the alphabet. For example, the following represents a Caesar cipher with a shift of 3: Plaintext: ABCDEFGHIJKLMNOPQRSTUVWXYZ Ciphertext: XYZABCDEFGHIJKLMNOPQRSTUVW (Notice that we are doing a circular shift, by wrapping the end of the alphabet around to the beginning.) To encipher a message, we simply take each letter in the plaintext, find that letter in the Plaintext row, and substitute the corresponding letter immediately below it, in the Ciphertext row. For example, using this substitution table, we can take the message: Once more unto the breach, dear friends and encipher into the following: Lkzb jlob rkql qeb yobxze, abxo cofbkap Of course, to decipher the text, we simply reverse the process -- or equivalently, use the negative of the original shift value. Question 1:
Here's the ciphertext for a message enciphered in the same way as above:
Qeb bkbjv mixkp ql xqqxzh lk Qrbpaxv jlokfkd What is the plaintext for this message? (This should be really easy! -- you can solve it manually, or use one of the Java Tools.) In reality, because case, word spacing and punctuation in the ciphertext give additional clues about the plaintext, they are usually removed, and the ciphertext is often organized into groups of characters. For example, the ciphertext in the example above would then look like the following: LKZB JLOB RKQL QEBY OBXZ EABX OCOF BKAP Of course, then it is the responsibility of the person doing the decoding to reconstruct the original word spacing, etc. Removing such clues from the plaintext before enciphering it makes it quite a lot harder to crack the cipher. Frequency Analysis on Substitution CiphersWhen attempting to decipher a shift substitution ciphertext, if you don't already know the number of characters to shift, of course, you need to figure it out. There are a couple of ways you might be able to do this:
MonoAlphabetic Substitution CiphersMonoAlphabetic Substitution Ciphers employ a more complex approach: Instead of using a simple shift to determine the letter mapping, they select an individual mapping for each character, where the relative position of the corresponding characters is, in general, different for all characters. So, in order to decipher a MonoAlphabetic Substitution cipher, you need to determine the mapping for every character -- a lot more complex than just determining a single fixed shift value. Here's an example of a MonoAlphabetic Substitution Cipher. Here's a letter substitution table for such a cipher:
where the top row represents the plaintext letters, and the bottom row represents the corresponding ciphertext letters. Using this table, we can encipher some plaintext into its corresponding ciphertext:
The top line is the plaintext, and the bottom line is the ciphertext. You can figure out how the translation is done by working through each letter of the plaintext, and matching it with the corresponding letter in the substitution table. So, given some ciphertext, how would you determine the letter substitution table? Again, you really have the same two choices:
How Do We Perform Letter Frequency Analysis?The brute force approach is pretty self-explanatory, so let's examine the Letter Frequency Analysis approach in more detail. First, we need to recognize that we're making some assumptions about the plaintext:
As long as we know that there is a 1-to-1, unique, mapping from plaintext to ciphertext (and therefore also from ciphertext to plaintext), we can employ our knowledge of those letter frequencies to help us crack a substitution cipher. Note that we need a large enough piece of text to give us some expectation that we have a large enough statistical sample. The longer the message, the better statistical sample we are likely to have. Sources of Letter Frequency InformationTo find known letter frequencies in typical English text, you can go to the following web sites, among many:
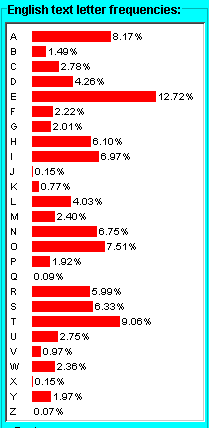
Here's a typical representation of the letter frequencies in typical English, using a histogram/bar chart:
The left hand side is in order by the letter position within the alphabet, while the right hand side is in decreasing order by frequency. Note that the twelve most common letters in English are famously:
(see http://www.worldwidewords.org/weirdwords/ww-eta1.htm) However, in the above histogram, the most common letters are:
Notice that the last letter is C, not U. This is a useful lesson in itself. Notice that the relative frequencies of U and C are 2.75% and 2.78%. That is, the frequencies of both are already quite low -- certainly when compared with E at 12.72% -- and also quite close. Different sets of English texts will produce slightly different frequencies, and the numbers are also subject to statistical fluctuations. Counting LettersSo, all we basically do, given a piece of ciphertext, is to count the number of occurrences of each letter, and from that build up a table that shows the relative frequency of letters in that ciphertext. Then we attempt to match it with the known English letter frequencies, and try to figure out corresponding letters -- and thus the substitution table. So let's try it with the following ciphertext:
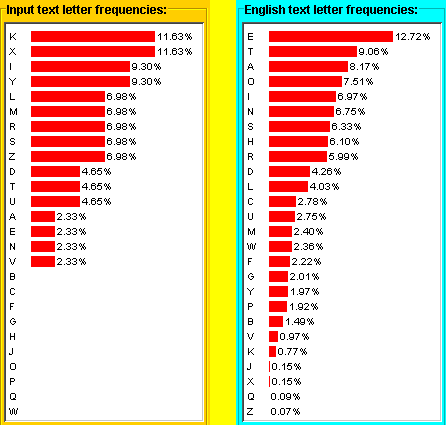
Well, we could actually count the number of each of the letters in this by hand. However, let's do it by computer. Here's what my program gives us:
So, let's make the simple assumption that the letters really do match up, based on the English letter frequencies, and that would give us the following substitution table:
(In this case, the top line represents the input ciphertext frequencies.) Then, if we use this table to try to come up with the corresponding plaintext, we get:
Clearly, not any plaintext that makes sense to me, anyway. So what's the problem? It could be that the plaintext doesn't follow the assumptions we made about letter frequency analysis. But it could also be that there isn't enough content in the ciphertext to give us reliable statistical information. Let's look at what the original plaintext really was:
and the substitution table was: where the ' ?' letters
represent "Doesn't matter', because the plaintext doesn't contain any of
the corresponding letters.
So, you'll most likely find that, with short ciphertexts, frequency analysis may not help you much. Consequently, the ciphertexts I'm asking you to decipher in this assignment are much longer than we've seen before, simply to give you the additional statistical significance. The AssignmentSo, here's what you need to do for this assignment:
What to SubmitFirst, refresh your knowledge of what I expect in an assignment report (and the format of that report). I want to see the following:
While it would be nice to see you come up with a correctly deciphered result in each case, I am much more interested in a detailed description of what you did, what you tried, what worked, and (especially) what didn't work, what your thought processes were, your frustrations, any suggestions you might have for improvements to the tool, and so on. How hard was it to solve these ciphers? How much work did you have to contribute, compared to what the tool contributed? Be sure to give credit where it was due, to all resources (human or otherwise) you used to solve these problems. |
| This page was last changed on February 17, 2008 |